
 Yesterday, we looked briefly at the Seven Sources of Problems and went 'around the clock' to get a general feel for what each source means.
Yesterday, we looked briefly at the Seven Sources of Problems and went 'around the clock' to get a general feel for what each source means.Today, we begin to work our way around the clock starting with source #1 - Acceptance into production.
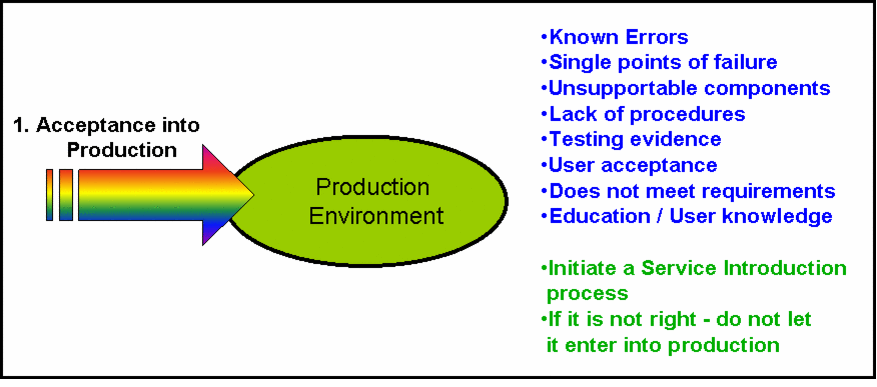
The multi-colored arrow is deliberatley multi-colored to represent the fact that any of the other 6 sources of problems could actually enter via this route into production and therefore cause a new problem.
The arrow is also 'broken' (left hand side) to represent that fact that generally most advanced IT Service Organizations have installed several "Quality Gates" to perform various checkpoints (say at design sign-off, or at the end of testing).
Such "Quality Gates" are meant to prevent poor quality systems and badly produced support documentation in the first place.
The ultimate aim here is to ensure that when the system reaches the final gate for introduction into production - it is known, supportable, the people are ready to begin supporting it and the services to maximise the value of the system for the business are in place and functioning correctly.
As we know all too well, quite often these types of tasks are either sacrificed if projects begin to run late - or - performed at the very last minute giving the impression that the system is "thrown over the fence" into production. This places undue pressure on Service Organizations and creates a reactive support environment. This, in turn, actually drives up the likely volume and frequency of problems due to inherent instabilities and inherent weaknesses in support capability. Service Level Agreement penalties are also prevalent.
So, what's the bottom line here? More problems occur when the support services for a new system (in the widest context) are not in place, rehearsed and the people present are capable of delivering that service.
So, what can we do about this situation?
Lots!
Here is a summary of some proactive actions that can be executed during the forthcoming system/service introduction - to prevent the above chain taking place:-
Known Errors:-
- Ensure that the Problem Management team have full visibility of all known errors way before the system goes live.
- If you can, allocate resource to proactively work with system and service testers to enable a better picture of the types, volumes and possible impacts that known errors might cause. Have that reources work dilligently with the testing folks to drive out as many known errors as possible.
- Use a risk/impact/exposure matric to ensure that the highest known errors are being tackled in the correct priority.
- Inevitably there will be some known errors that have to be accepted into production - but the key message is that they should be KNOWN, documented, service restoration workarounds already in situ as well as the support folks are per-educated to execute the restoration procedures.
- Finally all known errors should have a follow-up plan stating when their root cause will be eliminated and what resources/timescales are involved in doing so. Essentially, everything must be KNOWN.
Single Point Of Failure (SPOF) Analysis:-
- Involves identifying the weaknesses in a system or service design and either rectifying that weakness of eliminating it altogether.
- There is obviously a cost involved in installing highly resilient/redundant Infrastructure. Sometimes the business case doesn't fly with lots of expensive duplication options - so single units are opted for instead.
- Often the single points of failure are much more suble. They can be single filesystems that drive a new application, as opposed to actual hardware. SPOF's can also apply to human beings too!
- Think through if you have any single pojnts of people failure or single points of knowledge failure. Is there just one person who knows how to restore service for a given system?
- First identify your SPOF's, then risk assess them, then work to eliminate or reduce them to an acceptable level.
- If the resulting overhang is still looking risky - make sure that any SLA's you sign up to reflect the level of risk - in particular if it could impact availability.
Unsupportable Components:-
- It's often the case that many months after a system has gone live there is a component failure that no-one can fix anymore.
- Probably because the support resource has left the company or moved on, but also because the Vendor (with whom you have an underlying contract) has subsequently removed it from it's support portfolio.
- Even more subtle than this - is how Versions and Releases of components fall off a Vendor's support portfolio. Once again - list all components, ensure their supportability, keep a special calendar for upgrade paths and when certain version fall off the Vendor's support portfolio.
- This may seem like a lot of work and it is. However the overhead is made much easier when this approach is integrated into your Configuration Management Database structure. Each component CI should have these items recorded and tracked. Validating unsupprotable components then becomes as easy as producing a report.
- Where unsupported components ARE found - you need a supportability plan to execute against it. - If it's in production - it must be capable of being supported.
Testing Evidence:-
- Ensure that your Service folks get a good chance to review the results of any tests - before teh testing cycles complete. Getting a feel for the types of failures in testing and the remedial work necessary to overcome these bugs will provide a general indication about what types of problems can be expected later on.
- Keep in mind there will always be surprises!
User Acceptance:-
- Spending quality time ahead of implementation with your user community can also pay dividends.
- Get a feel for what kinds of bugs and issues your users are identifying
Does not meet (business) requirements:-
- If the end system does not do what it's supposed to do, say for a menu sub-option, and it's managed to creep it's way through testing and UAT, then it's going to hit the Service folks as a problem at some stage. Ensure via testing and user acceptance that the forthcoming system has been signed off and approved, in as many aspects as possible, by the business.
- Not meeting requirements also leads to a high level of early changes (post implementation). Such high volumes often lead to change failure (see source #2)
Education / User Knowledge:-
- Gaps in user education and knowledge oftne means that end users will quickly find local ways around overcoming the shortfalls in their new systems capabilities
- Such Gaps are often overcome in two ways: The use of excel spreadsheets (to manipulate data and perform calculations) and manual data manipulation. Both can cause considerably challenging Problems where the output produced does not match the desired business outcome or does not adhere to the business process/rules
- Gaps are important and should be closed as far as possible prior to acceptance into production
Finally, to wrap up today's post on source #1 - acceptance into production, we leave you with two guiding principles:-
(i) Implement a strong and well adhered to "Service Introduction" Process - to prevent poor quality and unsupportable systems entering production in the first place
(ii) Ensure Leaders have the strength of character to be able to say, "No", to new systems implementation - when there is enough evidence that an unnacceptable level of risk to the current operation will be introduced IF the new system is implemented.
In the next post, we will learn more about source #2 - Changes.
In the meantime if you have any comments or just wish to share your thoughts on the above topics - please post them below.


