
We've been busy creating a new look Blog covering nothing but the ITIL Foundation Exam and how to maximise your success with the multiple choice exam paper.
Now We Need Your Help!
For Dr. ITiL readers only - we are releasing for a limited time - probably only 18 hours or so - a pre-launch glimpse of the new Blog and we would really really value your feedback!
(Now please bear in mind that it's currently low on content and will need some tuning!)
However, we really want to know...
- Do you like the idea?
- Do you think it will prove useful for Foundation Students?
- What do you think of the layout / color schemes?
- What other types of articles / general improvements would prove useful?
Please post a comment below with your thoughts!! We'll take everything on board and get ready for the launch later on in the month...
You can reach the Blog here
Many thanks!
The Dr. ITiL Team.
Simple and Effective Process Flows - Chorus Systems
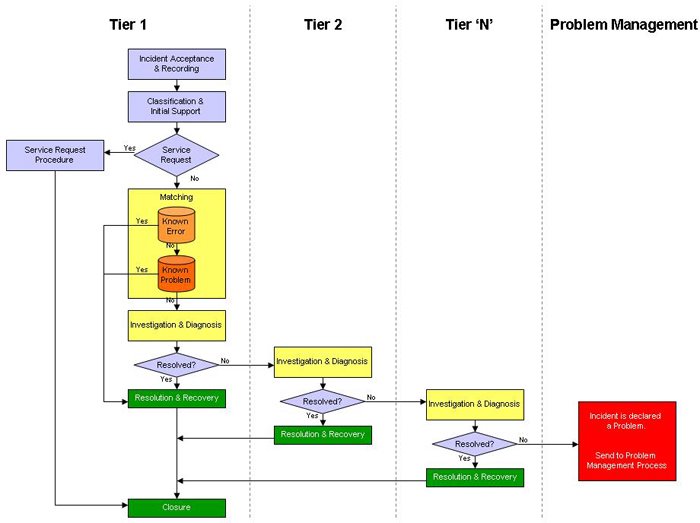
(Click to enlarge image).
We receive a lot of mails asking for good reference sources for process flow diagrams.
Visit www.chorussystems.com/resources for an ITIL primer and overviews of Incident, Problem, Change, Release and Configuration Management. Each section includes a color process flow chart that would make an excellent starting point for your own creations.
For example the above process flow is available at:-
http://www.chorussystems.com/resources/ITIL-Incident-Management.html
Check Out ITIL on the Wikipedia
In case you have not seen it yet - you can learn ITIL from the ground up (to a certain extent) on the Wikipedia - and you can edit and add new pages to share your ITIL knowledge with others.
Check Out ITIL on the Wikipedia
Check Out ITIL on the Wikipedia
The Seven Sources Of Problems - Full URL Version
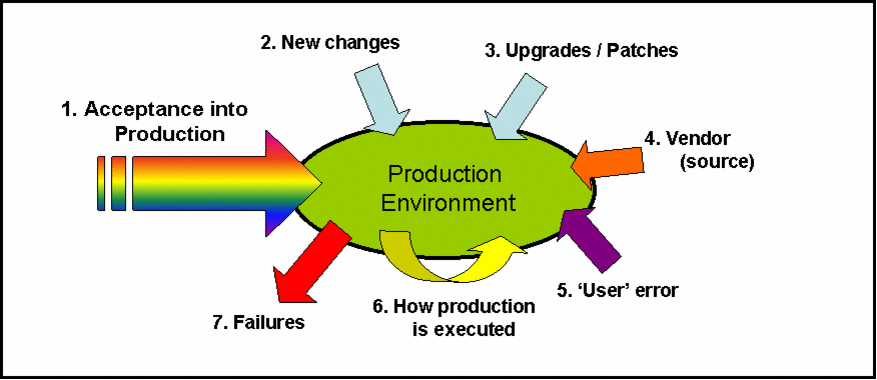
We received a lot of feedback on a recent series of articles based on the seven sources of problems. We have now updated this opening article with all of the links to each of the seven corresponding posts - to make it easier to absorb and enjoy.
We have planned a couple of follow-up articles on this topic, in particular how you use the seven sources model to strategically prioritize your 'areas of attack'. But for now, please enjoy this updated version...
On your next coffee break - take 5 minutes to think this one through...
There are only really 7 sources of problems. Yes - 7.
Every IT system, service, application or human problem can be traced back to these seven sources.
Over the next few days, Dr. ITiL will be publishing several (7!) follow-on articles where we will take you "around the clock" - from 1 through to 7 - and actually explain what each sources means and ways you can tackle it!
We've seen this time and time again in companies who are desperately trying to eliminate their problems to prevent any chance of recurrence.
Attacking the root cause of your problems is obviously the right thing to do!
However, you also need to get real tough on the sources of your problems - the real-world operating environment - in the widest sense of the term.
Incidentally, do you also investigate your "near misses"?
In the Airline Industry, where human safety is paramount, any planes found within a certain distance of each other that have to take evasive action - always have to follow through with a detailed report on how they got to that position in the first place and what they need to do to prevent a recurrence.
Imagine if your Problem Management team did the same?! The team would probably be considerably larger than it is today. Nevertheless, the seven sources model helps you consider not only actual "near misses", but potential "near misses" too.
The seven sources model is a reference model to accompany your thinking and improvement plans for Problem Management.
At the highest level and in a pretty down to earth style - we can summarise the seven sources as:-
[Links in Blue are now Available - Click Away!]
1. Acceptance into production - it got into your production world, you let it in, it caused a problem
2. New Changes - you let it through CAB, they implemented it, it caused a problem
3. Upgrades / Patches - you let them upgrade it (with or without change control), it caused a problem
4. Vendors / Suppliers - All of these categories, but considering suppliers instead of your local environment, they caused you a problem!
5. User Error - You let your Customer's use a system that they could break (bit unfair - some users will try hard to break their systems - albeit unintentionally)
6. How Production is Executed - The way you run your systems (re-scheduling batch processes, clock changes, deleting a job and it's dependencies fall over, you know the kind of thing!)
7. "Failures" - Electricity failure, mechanical breakdowns, elastic bands snapping
Click on any one of the links above to be transfered to the corresponding post.
New! Visit the latest Blog from the creator of Dr. ITiL – covering ITIL Version 3 Refresh, Service Catalogs, CMDB, Foundation Exam Tips and ISO20000 Knowledge. There’s a variety of free PDF and Powerpoint downloads available to help you plan and implement ITIL.
Visit the IT Service Blog
ITIL - The "Pre-Flight" Checklist
Here's a great little idea-jogger for anyone who is currently planning to implement ITIL in their organization. It's produced by the College of Continuing Education (www.cce.umn.edu).
It's a "pre-flight" checklist prompting you to think about whether certain activities and tasks have been completed.
Activities include:-
- Organization Support
- Baseline Assessment
- Scope of Implementation
- Training Strategy
- Implementation Strategy
- Certification Strategy
- Communication
- Resources
- Reporting
- Measurement
- Assuring On-Going Success
Take a look at the Pre-Flight Checklist
*Latest Resources*
New! Visit the latest Blog from the creator of Dr. ITiL – covering ITIL Version 3 Refresh, Service Catalogs, CMDB, Foundation Exam Tips and ISO/IEC 20000 Knowledge. There’s a variety of free PDF and Powerpoint downloads available to help you plan, implement, deliver and improve your ITIL environment.
Visit the IT Service Blog
New! Learn the Step-By-Step Proven Strategies for Successfully Implementing ITIL. Free Audio and E-Book Downloads - Plus Special Bonus Resources.
Visit Ask The Service Expert
It's a "pre-flight" checklist prompting you to think about whether certain activities and tasks have been completed.
Activities include:-
- Organization Support
- Baseline Assessment
- Scope of Implementation
- Training Strategy
- Implementation Strategy
- Certification Strategy
- Communication
- Resources
- Reporting
- Measurement
- Assuring On-Going Success
Take a look at the Pre-Flight Checklist
*Latest Resources*
New! Visit the latest Blog from the creator of Dr. ITiL – covering ITIL Version 3 Refresh, Service Catalogs, CMDB, Foundation Exam Tips and ISO/IEC 20000 Knowledge. There’s a variety of free PDF and Powerpoint downloads available to help you plan, implement, deliver and improve your ITIL environment.
Visit the IT Service Blog
New! Learn the Step-By-Step Proven Strategies for Successfully Implementing ITIL. Free Audio and E-Book Downloads - Plus Special Bonus Resources.
Visit Ask The Service Expert
A 'handy' tip for passing the managers/masters exam
One of the most under-rated and little known tips for passing the managers exam has nothing to do with ITIL whatsoever.
It's all about physical stamina and endurance.
Specifically, how long (and fast) you can physically write with a pen for.
This may surprise you - but those of us that have passed already will tell you that this is one of the most over looked areas of exam technique.
Think about it - you have two 3 hour papers to physically hand write, probably over two days. Excluding thinking and reading time - that's probably going to be about 2 to 2.5 hours physical writing per paper!
Points to ponder pre-exam:-
- When was the last time that you wrote for more than 5 minutes let alone 2.5 hours?!
- How legible will your writing be after, say an hour?
- Will an aching hand influence which questions you answer? (For example - will you steer away from an essay type question in favour of one of those 'split / multi-part' questions.
- What can you do to prepare yourself and overcome this often overlooked obstacle?
- Yeah sure you can write for three hours, no problem. But what about the following day when you come to sit the second exam? How's your writing hand feeling now?
OK, I've got to 'hand' it to you...here are some thoughts on what to do...
1. Stating the obvious first - please choose a pen (or several pens) that best matches your preferences. Some people prefer lightweight biros, others heavier gel pens. It's your personal choice - but make sure that you have written with that type of pen previously (for a couple of hours!) and you know it works for you!
2. In the build up to your Managers/Masters - do some writing every day to get those little used tendons moving and exercising again (typings quite a different thing!) Practice writing out some acronyms and set pieces to help you committ key points to memory. Try to build yourself up (like a marathon!) by doing a little more each day. Use your training 'mock' exam questions wisely to also introduce a mock test for your ability to write for long periods. Time how long you can write before needing a 'rest'. Know your own stamina levels.
3. As you begin the exam, make notes on the type of questions you will be answering, in terms of how much 'pen power' you will require. Try to alternate between questions that require a lot of writing and one's that do not - to alleviate the stress on your writing hand.
4. Throughout the exam, do simple hand stretches/flexes during your "thinking" time to help your muscles out.
5. After the exam, warm down occassionally over the next several hours, doing regular flexes to alleviate tension and prevent cramp.
6. If your second exam is the next day - make sure you relax your writing hand. You can buy sprays and ointments etc - whatever works for you.
In summary, you can be an ITIL expert in everything, but unless you can get pen to paper and write the actual words - you won't answer the questions in enough depth - and you will not pass the exam.
Now there's a 'handy' thing to know.
Dr. ITiL.
dritil @ dritil . com
It's all about physical stamina and endurance.
Specifically, how long (and fast) you can physically write with a pen for.
This may surprise you - but those of us that have passed already will tell you that this is one of the most over looked areas of exam technique.
Think about it - you have two 3 hour papers to physically hand write, probably over two days. Excluding thinking and reading time - that's probably going to be about 2 to 2.5 hours physical writing per paper!
Points to ponder pre-exam:-
- When was the last time that you wrote for more than 5 minutes let alone 2.5 hours?!
- How legible will your writing be after, say an hour?
- Will an aching hand influence which questions you answer? (For example - will you steer away from an essay type question in favour of one of those 'split / multi-part' questions.
- What can you do to prepare yourself and overcome this often overlooked obstacle?
- Yeah sure you can write for three hours, no problem. But what about the following day when you come to sit the second exam? How's your writing hand feeling now?
OK, I've got to 'hand' it to you...here are some thoughts on what to do...
1. Stating the obvious first - please choose a pen (or several pens) that best matches your preferences. Some people prefer lightweight biros, others heavier gel pens. It's your personal choice - but make sure that you have written with that type of pen previously (for a couple of hours!) and you know it works for you!
2. In the build up to your Managers/Masters - do some writing every day to get those little used tendons moving and exercising again (typings quite a different thing!) Practice writing out some acronyms and set pieces to help you committ key points to memory. Try to build yourself up (like a marathon!) by doing a little more each day. Use your training 'mock' exam questions wisely to also introduce a mock test for your ability to write for long periods. Time how long you can write before needing a 'rest'. Know your own stamina levels.
3. As you begin the exam, make notes on the type of questions you will be answering, in terms of how much 'pen power' you will require. Try to alternate between questions that require a lot of writing and one's that do not - to alleviate the stress on your writing hand.
4. Throughout the exam, do simple hand stretches/flexes during your "thinking" time to help your muscles out.
5. After the exam, warm down occassionally over the next several hours, doing regular flexes to alleviate tension and prevent cramp.
6. If your second exam is the next day - make sure you relax your writing hand. You can buy sprays and ointments etc - whatever works for you.
In summary, you can be an ITIL expert in everything, but unless you can get pen to paper and write the actual words - you won't answer the questions in enough depth - and you will not pass the exam.
Now there's a 'handy' thing to know.
Dr. ITiL.
dritil @ dritil . com
IT Service Delivery - We're Right in the Middle!
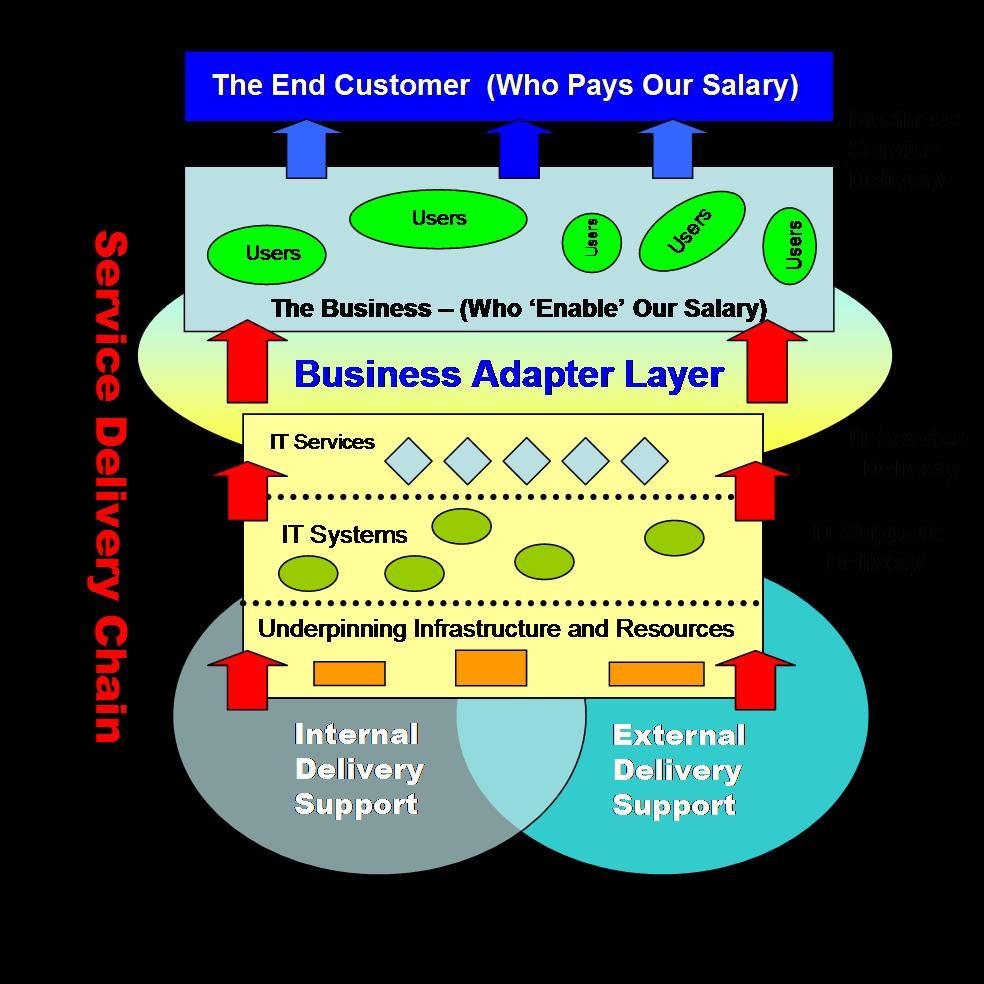 This picture simply illustrates the Service Delivery Chain (click to enlarge) from underpinning suppliers through to the end Customer (who pay our Salary).
This picture simply illustrates the Service Delivery Chain (click to enlarge) from underpinning suppliers through to the end Customer (who pay our Salary).Yet it's interesting to see that actually, when you take a step back, we're pretty much in the middle of this Delivery Chain. This obviously means we are positioned ABOVE the provision and management of Systems (Architecture, Hardware, Operating Systems etc) but BELOW something we're calling the Business Adapter Layer.
In true ITIL terms, Service Level Management takes care of this function, but in the real world we often find that business units have effectively created their own interfaces too. The VP of Customer Satisfaction, for example, will often create a position to "deal with those Technology folks" or "handle all my system issues".
There are several advantages to a business adapter layer:-
- Simplifies contact and communication channels
- Creates a focus point for ongoing communication
- Enables "good news" messages about the quality of service and service improvements to be driven through the business unit more easily
- Helps the business "get into" service, as and when they need something extra
- Easier for the IT Service Groups to obtain information, feedback and progress action items
- Great source of up-to-the-minute information about the actual business line itself
However, there are also disadvantages to the business adapter layer:-
- Bypassing the Service Desk for more routine requests
- Bypassing the Service Desk for reporting/tracking of Incidents
- Can become too powerful and mis-represent the business line
- Can become too demanding, in terms of expectations around service quality
On balance, when managed carefully, the Business Adapter layer can make a significant difference when interfacing with the Service Level Management Function. For complex businesses with intricate support requirements this adapter layer is essential.
Interestingly, you will often find that business adapter layers (that are business driven) are resourced with ex-technology/service people. People who have experience in both IT Service and the business line. [This is useful - but remember they will know all the right questions to ask and which corners to cut to get what they need faster!]
Looking to the next 5 years or so, with the advent of business process commoditization (the so-called business processes 'out of the box') IT Service Delivery processes will have a much more standardized and common set of interfaces and touchpoints for each business process. (see the link below for a re-fresher on this topic)
Read http://dritil.blogspot.com/2005/08/business-process-standardization.html
So, in a sense, common business processses will layout requirements which are satisfied by common IT Service Delivery processes (based on ITIL and CoBIT). Standard meets standard.
The key thing to note is this - IT Service Delivery Processes are standardizing far faster than Business Processes - which should be good news for future portability of your ITIL skills and experience.
We will build this model further tomorrow.
Real World ITIL - Implementation Tips

*NEW! Just before you get into this article - you may like to pop over to our very latest site "AskTheServiceExpert".
We have just prepared a free download of a special two hour Teleseminar covering ITIL Implementation Strategies.
You can access the replay, notes and special bonus resources.
To Learn More Click HERE.
Scott, over at Real World ITIL, has recently raised several excellent questions on his Blog about Real World ITIL implementation. If you have not read this Blog before you really need to check it out today. Lot's of interesting and complimentary advice over there.
We thought we would take each of Scott's questions, in turn, and have a good go at answering it here - and then post all the article back over for Scott's readers to absorb too.
Please feel free to add your own comments to this article. It's a healthy debate - and your ideas and experiences will be appreciated by many!
Key Questions (and Dr. ITiL's Answers):-
Should there be only one entry point into IT for incidents and other requests or multiple points-of-entry depending on type of request?
Like Highlander (seen the film?) - "there can be only one". What we mean is this - one entry point ensures that the IT Service Organisation has one version of the complete truth at any one time.
This helps to ensure that everything is prioritised for resolution (or completion) against everything else. Also, it ensures that related (linked) Incidents are tracked and a complete picture of what's happenning where - is maintained at all times. Multiple entry points leads to conflicts when Incidents are presented to Support people. Multiple entry points also means that Senior Management and the Customer will not necessarily receive timely, complete and acurate Incident updates whilst service is restored - a recipe for Service disaster.
Work requests should be prioritised differently and allocated to different functions for processing. In both cases the end-user should have access to online tools that ask the approriate questions to help drive the accuracy of incident or work request allocation.
• What process should be implemented to govern requests for IT services that are neither incidents nor ordinary service requests (e.g., a request for a new major project).
Also, how much latitude do our IT managers really have to deny a request for a service that is not defined in our Service Catalog? There should be a 'one stop shop' approach for ANY incoming request to the IT Service Organization - the Service Desk (the clue's in the name!!) The Desk can log and track all requests - however some 'out of line', unusual or out of service scope type requests should be allocated to hand-off points, such as "new project" type requests. Such a request can then be examined in more detail by the appropriate team and feedback provided.
This makes everything very simple for the end-user, the business and ultimately the IT Service Function. Most Service Desks are used to the opening line, "I don't know whether you can help me - but I would like to know.......". As for the second point, denying requests, the astute IT Manager should never say "no", but should learn to say, "Yes, however...". Everything is possible - but requests take time, effort and money to process successfully.
The Service Desk should direct difficult and unusual requests to some kind of predefined 'back stop' manager, who's responsible for reviewing and then re-allocating such requests. So, returning to our example (above) you would hear something like, "Yes, you can have what you need, however, it's going to need to go through the project approval process... and here's how you can do that..."
• Should root cause resolution be pursued for all problems or only the ones that had the highest negative impact?
I don't really agree with the 'either' / 'or' premise here. Also, we're assuming the question should have used the word "elimination" rather than "resolution". With only a few exceptions (later) ALL problems should have their root cause assessed, analysed and where possible eliminated. Where this cannot be done a business decision about "impact V's frequency of occurrence V's workaround effectiveness" should be made. Obviously, the higher the impact and frequency of occurrence - then the higher the priority of permanently removing the problem from production.
As for the exceptions, well they are generally based on two criteria:- "It's just not worth spending the time to eliminate that problem" (probably because the system is being upgraded or retired soon) and, "We can't find the problem - it's far too complex to eliminate - therefore (in agreement with the business) we will just 'live with it' for now". Not perfect - but certainly real-world!
• Should dedicated teams be organized around Problem Management, Service Level Management, Change Management, etc. or should there instead be “virtual” teams defined from the existing hierarchy?
Mmmm, very interesting question. Your first answer would always be, "yes, let's get some dedicated resources focussing on each team." However, this is massively influenced by the maturity level of ITIL within your organization. When you are in 'start-up' mode or you have just recently launched a new service function - you definately require dedicated and focussed resources to drive through the benefits of the function and ensure that the business receives the service that (some how) it's paying for.
Thinking ahead though, when things are bedded in and running more like clock-work (which is influenced by the rate of internal change!) you will want to more efficiently allocate resources to the service functions. Having an expert team of cross-skilled ITIL'ers capable of delivering against multiple functions is a very advanced way of working. [anyone doing this??] It's also a very cost-effective way of working.
My advice would be: start off by being dedicated, then get smarter and utilize your resource capability across multiple functions. Warning: It's advisable to still have the functional manager focussing on one, maybe two key processes. The resources underneath, who perform the real work(!), can be 'pooled' over time. This also gives them a more dynamic career path and ensures job enrichment.
• If we’re a global corporation, should there be only one Definitive Software Library at a single location to hold all master media, licenses, etc. or should it be distributed?
Yes, again the one version of the truth model applies here too. One complete picture removes the need for multiples copies, which can lead to inconsistent views and erroneous decisions being made. In reality, several Sub DSL's will probably feed into ONE master DSL, in a logical sense. Note: Local contracts, laws, information/property/storage restrictions can apply that make the one version impossible.
• Given that completing an actual physical inventory of IT assets is unfeasible and that automated tools can only discover a portion of our assets, how much inaccuracy can we stand in our CMDB and still have it be of value?
Ask yourself this: "What happens in each ITIL process when my CMDB is innaccurate for X% of the data I use?". For example, during Incident Management you need to know your Infrastructure topology to determine the Incident's impact and be able to correctly categorize the Incident. If your CMDB is missing assets - how can you do this?
Another example, the Change team are assessing the risks of performing a change on your live production environment but the CMDB information cannot see the linkages between the item being changed and any related items for another geographic location. How can you determine the true risk without an accurate picture? In the real-world, the cost of moving from 95% CMDB accuracy at any one time - to 100% is likely to be very high.
You need to weigh up the cost of achieving and maintaining 100% V's 'the impact to service of <100%.>
If your team feels that you've settled for, say, 80% than that's all you'll ever get.
• How do we define “overprovisioning” and “underprovisioning” with respect to Capacity Management? Should we for instance establish a policy such as “we will manage infrastructure capacity to within +/- 10% of actual client demand for service?”.
In our view, Client Demand differs greatly from "what you need to effectively run the service - and keep it running!" Clients are humans too and will always go for whatever the maximum is. They don't want any downtime as a result of a system running out of capacity and neither do you.
In this example any past experiences with the level of demand should also be factored into the decision making process. So, for example: If the Client has (or is likely to have) high levels of new users on any system, but with incredibly short notice (that's if you get told at all!) then you know that you need to run capacity with an in-built slice of capacity to accommodate this scenario. Subject to SLA's, contracts etc.
In our experience - especially where resources are relatively inexpensive compared to the impact of downtime (e.g. Disk, CPU, Bandwidth) you should aim to keep between 15%-25% capacity free, when balanced against the potential to actually use it, the costs of providing it (and maintaining it) and the Clients demand profile. We find it rare that systems are so nailed down, change so tight and the Client so well informed that everything run, "just in time at the optimum level".
• What are the three most essential governance metrics that our processes should generate for management purposes?
[1] Satisfaction with Service Availability, [2] "Under Control", [3] Future-Proofed delivery.
Ok, we've tried to be clever and make some thing high-level and generic. But for me the most important aspects of delivery are:
[1] Is the Client and your board satisfied with your level of delivery against Service Levels - Are you delivering what you need to - to the Clients Satisfaction?
[2] Is everything "Under Control"? Are you managing your Audits, issues, risks, maintaining standards, delivering against KPI's, hiring people fast enough - there's a big list of things that fall under this category.
[3] Are we continuing to do the right things, at the right time, to assure and future-proof the delivery of service today, tomorrow and in a years time.
• How much influence should the Financial Management team have over the control of other service delivery processes? How much effort should we put into developing a cost transparency model for our processes?
None. It's not the Finance teams' role to control any other Service Delivery Function. However, they directly influence, impact and enable (all at the same time) the resource and cost levels apparent within the other Service Functions. This then determines the quality, scope and capability of the team [people, tools, training,etc].
As for transparency, this will depend on your desired cost-model and how the Client has opted to pay for the service it receives, via the Contractual terms. Smart outsourcers know, hoever, that transparency gives them greater scope for making ongoing cost casvings - and therefore helping them to increae their margins faster over a shorter time period - so they will opt for greater transparency. A smart Client will be keen to understand who they pay for , in terms of service delivery, and what saving they can make over time - this reduces the Outsourcers revenue stream. Natural tension or Tough Love? It all happens in the real-world!
Anything to add? Why not post your own views below and add to the debate.
An Important Note About Yesterday's Article.
Yesterday - we made a mistake - the first one in eight months of publishing Dr. ITiL - which we would like to correct publicly here.
In the publishing process yesterday, we did not include a reference to the originator of the headings for the "Top 10 reasons for ITIL Implementation Failures". We apologise to Malcolm Fry and associates and have correctly credited this today.
However, in our opinion, the underlying content is original and actually adds to Malcolm's headings.
Dr. ITiL is not in the business of passing off other people's work. We provide a much used public service and wish to uphold the highest professional standards. We have responded directly to yesterday's comment and have re-published the article with the correct acknowledgements.
(Click on the Comments below to read the full story).
--------------------------------------------------------------------------------------------------------------------------------------
The Top 10 Reasons in this article are accredited to Malcolm Fry. This article was inspired by Malcolm's insight and provides further comments in support of overcoming the Top 10 reasons why ITIL implementation Fail.
For futher information on Malcolm Fry - please visit:-
Top 10 Reasons for ITIL Failure
Implementing ITIL takes dedicated effort, active executive sponsorship and a little bit of magic from those executing the programme to ensure that everybody's on board, bought in and proactively helping to embed new processes, procedures and toolsets.
It's quite a challenge - but the rewards are worth it!
Today, Dr. ITiL looks at the often quoted "Top 10" reasons for ITIL implementation failure and offers some 'front-line' pragmatic advice on how to overcome them. Note: These reasons originated from Malcom Fry and have entered the public domain and seemed to have 'stuck' as the most quoted reasons for failure, based on Google searches.
If you enjoy the article - why not join of FREE E-Zine list today - to ensure you receive bonus articles and materials not available on this site.
If you don't enjoy the article - then have your say - post a comment and let everyone know what you think...
OVERCOMING THE REASONS FOR FAILURE:-
1. Lack of management commitment
- You need senior commitment from the start since ITIL implementation is really large scale transformational change; people, working practices, meetings, reports, tools, management information - it's all going to change dramatically - so make sure the people at the top "feel the value" that ITIL is going to deliver.
- Deliver some 'quick wins'
- Solve some 'nagging' issue that the CEO/Senior Management have never really managed to 'crack' using just one concept/best practice from ITIL
- Look for a "MUST DO" reason to obtain executive sponsorship - BS15000 and ITIL are now often included in Service Contracts to ensure that the client/customer will deliver to a high standard
- Let the CEO know how many other Fortune500 / FTSE 250 companies are now heavily investing in ITIL
- Let the senior management learn more about ITIL without their learning experience being embarrassing or expecting a decision from them - 'there and then'
- Give them the web link to www.dritil.com
2. Spending too much time on complicated process diagrams
- Just as the technical guys can create 7 different auto-fail-over options for your server recovery programme, ITIL boffins can blind people with wonderfully complicated process maps, linkage points and 'swim lanes'. Be aware of who is 'selling' ITIL upwards. Put the right people in front of the CEO
- As your implementation programme develops - ensure that it remains pragmatic and focused on your defined deliverables
- Start process diagrams simple and high level - the underlying detail is easy to add - but it must remain true to the higher level
3. Not creating "work instructions"
- The typical hierarchy is (a) Policy Document, then (b) Process Document, then (c) Procedure Document and then finally (d) Work Instructions
- Work instructions are sometimes overlooked but are critical to ensuring that different people can execute steps within a procedure consistently, accurately and to a high quality
- Creating and changing Work Instructions is a bit of an art, but there's bound to be someone in your organization that actually enjoys writing them...and gets them done quickly too. Find them!
4. Not assigning process owners
- Assign an owner to each process and keep them separate if possible
- Empower the owner to really "own" their process - make sure they are passionate about it's implementation, delivery quality and continuous improvement
- A process owner should be like the owner of a famous restaurant - always delivering high quality, fussing around customers to ensure they received a great experience and improving everything based on customer feedback
- Some people like owning processes, some do not. Find the right people
5. Concentrating too much on performance
- Handling large volumes through processes is fine - but how well are you handling them?
- Quality delivery is important once the excitement of handling the initial volumes through the process are over
- The recipients of service will not be impressed by numbers - only the quality dimensions of what they receive, like timeliness, accuracy and completeness.
- Allocate some resource to measuring the quality of process outputs
- Target aspects of your ITIL implementation with the delivery of quality in mind from the outset - this will save re-work and expense over time
6. Being too ambitious
- Eating the Elephant in chunks is the order of the day!
- But the chunks must be tackled in a logical order - not a scatter gun approach. Keep control over who's doing what, and when, by setting up a small pragmatic ITIL implementation Center (similar to a programme office). The office should be empty most of the time because all you really need is a structured plan and buy-in from all concerned
- Remember ITIL implementations can be delivered in phases of maturity as well as the delivery of each process. Start by getting the most 'bang for your buck', revisit to tweak the detailed items later.
- Standing back and taking a holistic view of what you delivered and how it's operating after a few weeks will prove very valuable indeed. This technique should be built into the overall delivery plan for ITIL
7. Failing to maintain momentum
- Running out of steam mainly happens because management 'gets bored' or another corporate fire needs putting out somewhere else
- Implementing ITIL is not seen as 'sexy' because it's process and procedure orientated
- Recognize that momentum will fall away and try to time the delivery of key items to help push the momentum along
- Have a breather; allow some time for reflection between major phases of your programme, then build a groundswell of momentum by announcing the start of the next phase - building on the success of the last phase
- Internally, it may be advisable to be seen to use ITIL to complement another major initiative such as Sarbanes Oxley or Six Sigma. Partnering ITIL with other objectives will help embed it further in the organization
8. Allowing departmental demarcation
- Set shared goals across the organization to help prevent demarcation
- Sometimes passionate process owners can get too precious about their patch. Use the defined interfaces and hand-off points (as described in the Red and Blue Books) to show you where to set shared goals. This will reduce the likelihood of conflict
- Rotate process managers every 3-6 months. This allows managers to build up an insight and detailed appreciation of other processes and will remove demarcation points since the manager knows that they may be moving into a certain process area in a few months
9. Ignoring solutions other than ITIL
- Use other best practices and corporate frameworks to give ITIL a boost and help embed it into the organization such as COBIT, Sarbanes-Oxley and Six Sigma
- People performance and Supplier performance are also important
10. Not reviewing the entire ITIL framework
- "If I had my time again", said one ITIL Implementation Consultant, "I would have started with a fresh piece of paper and wrote the words Configuration Management in the center. Everything else is built around that configuration heart. It pumps and feeds the other processes. What we have done here is to rush out and implement a helpdesk, then Incident, then Problem, then some Change...then we realized...Configuration Management is the key to everything. Sharing information across the processes provides a massive ROI for any ITIL implementation. As things stand we now have to spend a lot of time re-working things to retrospectively re-fit Configuration Management"
- ITIL is wider than just Service Management (you knew that right?) it also includes:- Security Management and the ICT infrastructure management books. Learn the wider boundaries about what ITIL can offer before embarking on a major implementation exercise.
Kickstart Your ITIL Implementation (or improvement) Programme
Since 2000, Gene Kim and Kevin Behr have met with hundreds of IT organizations and identified eight high-performing IT organizations with the highest service levels, best security, and best efficiencies.
For years, they studied these high-performing organizations to figure out the secrets to their success. Visible Ops codifies how these organizations achieved their transformation from good to great, showing how interested organizations can replicate the key processes of these high-performing organizations in just four steps.
What is Visible Ops?
The ITPI (The Information Technology Process Initiative) developed the Visible Ops methodology because they could not find any satisfactory answer to the question: "I believe in the need for IT process improvement, but where do I start? What do you implement first, and how do you do it.
Other information, publicly available from a variety of sources, is too general and vague to effectively aid organizations that need to start or enhance process improvement efforts.
The Visible Ops Handbook provides a prescriptive roadmap for organizations beginning or continuing their IT process improvement journey.
>>Read more<<
For years, they studied these high-performing organizations to figure out the secrets to their success. Visible Ops codifies how these organizations achieved their transformation from good to great, showing how interested organizations can replicate the key processes of these high-performing organizations in just four steps.
What is Visible Ops?
The ITPI (The Information Technology Process Initiative) developed the Visible Ops methodology because they could not find any satisfactory answer to the question: "I believe in the need for IT process improvement, but where do I start? What do you implement first, and how do you do it.
Other information, publicly available from a variety of sources, is too general and vague to effectively aid organizations that need to start or enhance process improvement efforts.
The Visible Ops Handbook provides a prescriptive roadmap for organizations beginning or continuing their IT process improvement journey.
>>Read more<<
Welcome to Dr. ITiL - IT Service Management Fun!
Welcome to Dr. ItiL, the world's largest Service Management Blog that's actively updated and carefully releases fresh new articles, white papers and Service Management News.
In case this is your first time over here (what took you so long?) we want to be seen to be friendly and giving... if you've been here before to visit us then you know just how giving we actually are.
We only exist to share best practices, new ideas and great content on any IT Service related topic.
Here's some of the things you've missed since we launched way back in February this year:-
Introduction to ITIL:- background, pocket guides, presentation packs, history, basic concepts:-
http://dritil.blogspot.com/2005/07/itil-service-support-and-delivery-free.html
http://dritil.blogspot.com/2005/07/free-itil-pocket-guide.html
http://dritil.blogspot.com/2005/05/itil-essential-links.html
http://dritil.blogspot.com/2005/07/grasp-essentials-of-itil-in-only-30.html
FREE ITIL Deliverables:- guides, templates, checklists and useful presentation material:-
http://dritil.blogspot.com/2005/07/free-process-management-guides.html
http://dritil.blogspot.com/2005/07/back-to-school-learn-itil-from-ground.html
http://dritil.blogspot.com/2005/06/free-41-page-guide-to-incident.html
http://dritil.blogspot.com/2005/06/implementing-or-improving-problem.html
ITIL Exam Tips:- Foundation study guide, exam hints and guidance, articles:-
http://dritil.blogspot.com/2005/08/free-study-guide-itil-essentials-pass.html
http://dritil.blogspot.com/2005/06/get-edge-itil-exam-tips.html
http://dritil.blogspot.com/2005/07/taking-itil-managers-masters.html
ITIL Implementation:- how to implement, best practices, what to avoid, pitfalls, mistakes:-
http://dritil.blogspot.com/2005/07/implement-itil-in-5-steps.html
http://dritil.blogspot.com/2005/07/how-to-implement-itil-with-six-sigma.html
http://dritil.blogspot.com/2005/07/itil-implementation-best-practice.html
http://dritil.blogspot.com/2005/05/implementing-itil-some-common-errors.html
http://dritil.blogspot.com/2005/04/how-to-help-your-organization-overcome.html
You will also find additional bonus articles hiding away within the categories over on the left - so give them a click and see what you find!
Have you joined our special mailing list yet? No?
You can sign up for free over on the sidebar on the left. You will receive a bi weekly E-Zine containing special content not available on the site - plus coming soon - new about the forthcoming brilliant new forum site - where you can exchange news, views and debate about IT Service Management stuff!
The Seven Sources of Problems #7 - "Failures"
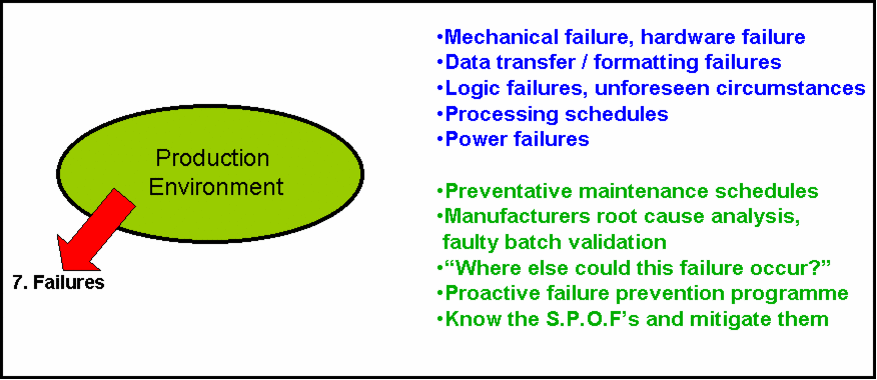 In this final articles in the series, "The Seven Sources Of Problems", we look at Source #7 - "Failures".
In this final articles in the series, "The Seven Sources Of Problems", we look at Source #7 - "Failures".In this context we mean everything that could fail and have an impact on service or your capability to provide service; but not due to the other sources of problems, such as changes, upgrades, or suppliers.
"Things just sometimes fail". That's why we have maintenance contracts. That's why we have health insurance come to think of it.
There are a number of areas where failures can directly impact service provision and reduce availability:-
•Mechanical or hardware failure
•Data transfer or data formatting failures
•Logic failures
•Processing schedule failure
•Power failures
Now, there will often be a 'cause and effect' challenge; for example - the air conditioning system would not have failed if we had realised that there was an extra load on it due to 100 new business users starting in that building last week.
So, What can you do about source #7 - failures?
There are several working practices that can be adopted to help relieve the pressure of new problems coming from this particular source:-
Preventative maintenance schedules. Not only the schedules but the actual smooth execution of the work. Talk to your facilities team about their schedules too. Why not combine schedules to work effectively together to minimise overall downtime to the business? For every component you should be able to determine its health, it current status and when it might be due a check-up from the maintenance teams.
Manufacturers root cause analysis, including faulty batch validation. It's amazing how many times you have a problem - say due to failure - but you don't realize that you're not the first, and you're not alone. Manufacturers and systems integrators occassionally suffer from potential mass failures - and sometimes need to perform an emergency field upgrade (to prevent the failure) or an emergency field upgrade (note - same title!) to replace a failing/ed item. It's important when these occur to check your full inventory for any other similar / realted items and also ask the Vendor / Manufacturer whoch 'batch' did those failing items come from, what is the root cause of the problem - and most importantly - will the new item work? How do they know? What if the same symptoms occur again? Ask tough questions - because you have been impacted.
“Where else could this failure occur?”. Simple question - but it's often effective at obtaining an answer that helps to prevent further failures. When you get impacting by a failure - ask yourself this question. Take action to prevent similar failures elsewhere. For example if you have four highly redundant, all singing, all dancing super powerful Routers and one suffers a power supply failure and shorts the entire backplane - taking it our of service... then what ensures that the other three won't suffer the same sometime soon? People will give you a hundred reasons why it was a "one in a million" - but is it really?
Proactive failure prevention programme. Sounds a bit grand this one doesn't it? But you will be pleasantly surprised if you just call in your top support people, along with the facilities team and some of your key vendors and just "brainstorm" this topic for a couple of hours. I suspect they will tell you a few home truths about cable infrastructure, labelling accuracy, items that failed maintenance and have not been replaced or re-checked. It's real-life and these things happen. But getting everyone together and creating the right atmosphere where people can contribute and help to identify the most likely items to fail - is really useful.
Know your S.P.O.F’s and mitigate them. Identify, hunt down and eliminate (or mitigate) single points of failure, where you can afford to do so - or afford to accept the risk of not eliminating the SPOF. Single points of failure can also be at a logical, rather than a physical level, especially with network configurations and databases. So, keep your perspective pretty broad on this topic.
As a final point on the Seven Sources model, you should consider the initiatives, tactics and general approach to the actions required holistically, rather than in silo's across the individual sources.
An integrated programme apporach, where you keep costs low by improving the way that your support people currently work, is recommended.
Everything we've listed here is not really 'rocket science' but within our ever changing environments it's key to keep on top of these initiatives to prevent problems in the first place.
I guess this old saying sums it up...
"Problems are not like wine - they don't get better with age!"
The Seven Sources Of Problems #6 - Production Execution
Last week we introduced the “Seven Sources of Problems” framework and listed the core seven sources for all production problems.
Today’s articles highlight source #6 – “Production Execution”
This source looks directly at the actual way that Operations, Production Support and any other maintenance and support function delivers the service they need to deliver to ensure non-stop continuous operations for a demanding commercial organization.
The way we actually manage, control, change and improve our production environment correlates the volume and frequency of new problems.
Stop/Start recovery procedures. Failing to have adequate stop/start procedures for your core Infrastructure, job scheduling, databases and other application support mechanisms will ultimately lead to new problems. It’s all about being in control. Can your IT support teams effectively take down and then, after some remedial action has been taken, start service again.
The goal is minimum impact and disruption. It is important to note that a significant proportion of new problems often stem from the way that service weas taken down and/or restarted. We have counted numerous times that either for routine (non service impacting) maintenance or during the life of a run of the mill incident, incorrectly executing ‘stop’ procedures or inadvertantly executing the wrong start script without due consideration to the time of day and the end state of the systems, can lead to far greater problems than necessary.
Checkpoints:-
- Have you mapped all your underpinning Infrastructure to a Service Map – so you know what needs to be available to drive your service?
- Have you clear and unambiguous stop/start procedures that are known and understood?
- Do your people know how and when to execute these procedures?
- Once service has been restored, are all data feeds and file transfers as you would expect them?
Automated tools and the ability to handle out of line situations. Tools are great – they cut down on human interventino and help us to manage moer effectively. However, the modern plethera of tools and their in-built complexity often means that they “sprawl” out on their own and no-one really knows what’s happenning with them, in terms of when they execute their own housekeeping, tidy-up routines and perform their core processing. To this end, when problems occur and the root cause requires rapid identifiaction and elimination – you really need to use the full power of your diagnostic tools to assist.
Checkpoints:-
- Have you got the right tools, measuring and capturing the right things?
- Will you tool configuration proactively support your problem management process?
- Are your tools paying off? Do you spend more time ‘tuning’ them – than they do providing benefit for your environment?
Impact of changes on production schedules, in particular business/environmental changes. The key point here is really simple, when aspects of service change (start time, number of users, new interfaces) does your underlying processing also change? There are many occurrences where the business aspect changes, but someone back in Operation forgot to re-schedule or re-design the overnight processing flows to accommodate these changes – resulting in new problems.
Checkpoints:-
- Are tools and scheduling products automatically linked to your change management process?
- Have you got your processing sachedules really ‘nailed down’ and under control?
- If an overnight job fails, are clear re-start instructions in place for your teams to continue processing without the need to call for support?
Human error. Final area to explore in this source of problems – but perhaps the most important. Human intervention by support teams, service teams and the business admin people can lead to procedures being executed incorrectly and errors made that cause new problems. It is critical that this source of problem is identified and the relevant person understands and knows ‘the error of their ways’. The biggest reason why people do not own up to human error is because their working environment suffers from a ‘blame culture’. Our advice is simple, eradicate any ‘blame culture’ and focus on a building a supportive culture with education to help people fully understand how to d othings correctly first time.
In the final part of this series of articles we explore source #7 - "Failures" where we recommend some key actions to help minimise how this source can impact your environment.
Today’s articles highlight source #6 – “Production Execution”
This source looks directly at the actual way that Operations, Production Support and any other maintenance and support function delivers the service they need to deliver to ensure non-stop continuous operations for a demanding commercial organization.
The way we actually manage, control, change and improve our production environment correlates the volume and frequency of new problems.
Stop/Start recovery procedures. Failing to have adequate stop/start procedures for your core Infrastructure, job scheduling, databases and other application support mechanisms will ultimately lead to new problems. It’s all about being in control. Can your IT support teams effectively take down and then, after some remedial action has been taken, start service again.
The goal is minimum impact and disruption. It is important to note that a significant proportion of new problems often stem from the way that service weas taken down and/or restarted. We have counted numerous times that either for routine (non service impacting) maintenance or during the life of a run of the mill incident, incorrectly executing ‘stop’ procedures or inadvertantly executing the wrong start script without due consideration to the time of day and the end state of the systems, can lead to far greater problems than necessary.
Checkpoints:-
- Have you mapped all your underpinning Infrastructure to a Service Map – so you know what needs to be available to drive your service?
- Have you clear and unambiguous stop/start procedures that are known and understood?
- Do your people know how and when to execute these procedures?
- Once service has been restored, are all data feeds and file transfers as you would expect them?
Automated tools and the ability to handle out of line situations. Tools are great – they cut down on human interventino and help us to manage moer effectively. However, the modern plethera of tools and their in-built complexity often means that they “sprawl” out on their own and no-one really knows what’s happenning with them, in terms of when they execute their own housekeeping, tidy-up routines and perform their core processing. To this end, when problems occur and the root cause requires rapid identifiaction and elimination – you really need to use the full power of your diagnostic tools to assist.
Checkpoints:-
- Have you got the right tools, measuring and capturing the right things?
- Will you tool configuration proactively support your problem management process?
- Are your tools paying off? Do you spend more time ‘tuning’ them – than they do providing benefit for your environment?
Impact of changes on production schedules, in particular business/environmental changes. The key point here is really simple, when aspects of service change (start time, number of users, new interfaces) does your underlying processing also change? There are many occurrences where the business aspect changes, but someone back in Operation forgot to re-schedule or re-design the overnight processing flows to accommodate these changes – resulting in new problems.
Checkpoints:-
- Are tools and scheduling products automatically linked to your change management process?
- Have you got your processing sachedules really ‘nailed down’ and under control?
- If an overnight job fails, are clear re-start instructions in place for your teams to continue processing without the need to call for support?
Human error. Final area to explore in this source of problems – but perhaps the most important. Human intervention by support teams, service teams and the business admin people can lead to procedures being executed incorrectly and errors made that cause new problems. It is critical that this source of problem is identified and the relevant person understands and knows ‘the error of their ways’. The biggest reason why people do not own up to human error is because their working environment suffers from a ‘blame culture’. Our advice is simple, eradicate any ‘blame culture’ and focus on a building a supportive culture with education to help people fully understand how to d othings correctly first time.
In the final part of this series of articles we explore source #7 - "Failures" where we recommend some key actions to help minimise how this source can impact your environment.
Your Service Catalog:- Special Delivery = 60 Days
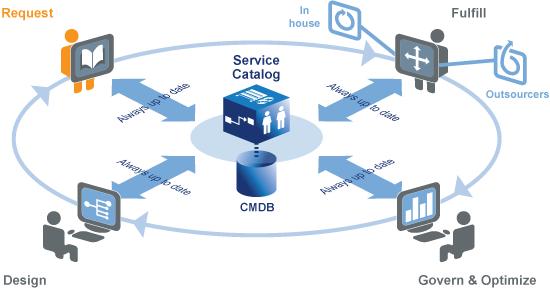
Centrata's (www.centrata.com) got a "Service Catalog Accelerator" which sounds like something right out of Star Trek (TOS of course!)
From their site we learn that if offers:-
- Rich out of the box content that covers over 70 percent of common IT services and associated workflows out-of-the-box, saving you time and delivery industry best-practices
- The ability to leverage your catalog and enable standardized demand management through a web-based request portal
- Out of the box reports and dashboard capabilities to deliver service visibility and enhance IT planning and optimization
- You can achieve all of these benefits from your catalog in as little as 60 days
Now, it's the last point that we REALLY like!
I've contacted Centrata via e-mail to ask them if they would like to provide us with a special guest article on how this is achieved.
And further on we also learn:-
"By deploying Centrata’s Service Catalog Accelerator, you’ll guarantee results:
- Improved Quality & Predictability of IT by standardizing IT
- Reduced Costs by improving operational and capital efficiency
- Improved Customer Satisfaction by setting expectations and proactively communicating IT’s value
- Improved IT – Business Alignment by focusing IT on what’s business-critical through actionable SLAs"
It's not that I'm sceptical - I've just been around for a while - so, if this product really does the trick then its going to be extremely valuable to a lot of us in our ITIL quests.
In the meantime - if anyone's got any first hand practical experience please let us know by posting a comment below...
Learn More About Service Catalogs Here...
Ten Tips for Successfully Implementing ITIL - A Critique by Dr. ITiL
We read loads of articles every week claiming to know the "secrets" of ITIL implementation, offering half-baked ideas and money-for-old-rope approaches.
To be honest most of them are rubbish - but Isabel Wells (writing for CIO update) seems to have touched a few of our buttons.
So, we decided to give her top 10 implementation tips a good walk through and based on our collective experience, provide some feedback to each point, as follows.
[to read the original article in full, click here ]
Top 10 Tips for ITIL Implementation - Plus critique by Dr. ITiL
1. Approach ITIL implementation as part of the IT-wide strategy, and use it to guide all other strategic initiatives.
-ITIL process implementation has significant IT-wide impacts; it is not an isolated initiative. * TRUE.
-To avoid both resource and programming constraints, implementation must be aligned with other global and regional programs, IT initiatives and sourcing or supplier initiatives. * TRUE, as with any large Programme.
-A portfolio management approach should be taken to understand the alignment and priorities of all initiatives in addition to the overall benefits to the organization. * TRUE, though this is standard with any large Programme.
2. Consider the post-ITIL organization before completing the process design.
-Introducing ITIL-based processes generates requirements for new functions and roles, which could impact the current service management structure. *Absolutely. Different people are required to perform different duties, at different times. This is certainly one of the most challenging – but often NOT thought through areas of implementing ITIL. The new organizational structure is also a potential source of much discomfort for people, if communication and transformation planning is badly handled. People need to know where they are going, the benefits to be sold to them personally, and they need support and guidance with making an effective transition. *Warning: Sizing Service Teams is notoriously difficult. Can anyone point to “sizing models” that offer excellent guidance? I have never seen any. Usually sizing service teams is based around part considered workload analysis and ‘best estimates’. Hardly scientific!!
-Prior to completing process design, understand the roles and functions required to support the processes; giving specific consideration to the supplier/internal resource split. *Good thought. The internal changes in structure and roles, should also lead directly to a complete re-think on the roles and responsibilities of Suppliers. This could, in turn, lead to contractual re-negotiations. Depending on resource levels internally, there could be an opportunity to either out-task more responsibility to Suppliers, or to reduce contract costs and take more responsibility on in-house.
-Consideration must also be given to the governance structure needed to guide and support the new IT organization. Establishing a transformation program ensures that the structure from which to hang ITIL is secured and operational prior to process implementation. *Totally agree. Excellent governance (say, with a transformation board) to regularly monitor progress and assist programme managers by resolving their issues and mitigating risks can make ‘all the difference’.
3. Engage, engage, engage. Continuous communication is required at all levels of the organization.
-Implementing ITIL impacts the full spectrum of the organization’s employees. Because of this, it is critical to understand the impact at each level within the organization and the value each brings to the program. *Understanding – at all levels – is only the first stage though; the second point is where the action happens…see communications below…
-Subsequently, engagement, communications and training are absolutely key to success; from the initial engagement of senior stakeholders to the manager-level ITIL training of new global process owners. *Engagement and communications shouldn’t just stop at the manager level though. EVERYONE should receive appropriate briefings, especially analysts and coordinators who do the ‘real’ work everyday!
4. Set realistic expectations about benefits realization and establish a baseline from which to monitor improvements.
-Change within any organization takes time to be accepted and implementing ITIL is no different. Implementation of ITIL focuses on improving customer service and as the processes mature the subsequent ROI will be recognized. *Fine in theory, however how many of us actually went back and proved that the ROI was delivered within a suitable timeframe? It’s recommended that ROI be measured (a) before process implementation, (ii) a few weeks after, then (iii) as the process moves up the Capability Maturity Model. Note individual (or pairs) or ITIL proceses should be measured as opposed to the whole entire effort. ITIL is best implemented in a series of well executed, smaller projects.
-To determine the end result, focus the strategy and focus communications on improving service quality and establishing an early baseline of key performance indicators (KPIs) from which to monitor improvements. The chosen KPIs and their associated benefits should be business-focused and clearly understood so that effort is not wasted on measuring and interpreting superfluous data. *Good Advice.
5. Engage existing suppliers early.
-Existing suppliers and any subsequent SLA’s will be affected by the implementation of ITIL. The strategy for handling third-party engagement and establishing a robust communications plan must be clearly defined, with priorities focused on the desired supplier landscape. *Agreed.
-Early engagement with procurement and legal departments will help to support and address the ripple effect that occurs right through to existing contracts and SLAs upon implementing the new processes. An end-to-end SLA will also be ultimately required to support the operation of the new processes. *It’s not strictly true that SLA’s and contracts need to be changed just because you’re implementing ITIL – although if you’re implementing it successfully – then you will probably want to realise cost savings and change specific SLA targets / KPI’s. But it’s not mandatory to have to change contracts – it’s more about re-enforcing what you are aiming to achieve with your ITIL implementation.
6. Process
Identify and deliver the quick wins.
-It's "old" advice, but it remains fundamentally important to ensure that the organization achieves, communicates (and celebrates) early successes. *Absolutely! Deliverer a series of rapid, successive, well-executed quick wins right the way through your ITIL implementation programme. You need to keep everyone’s interest and keep generating positive news about the programme. For every process you implement there should be critical success factors defined in advance. Also, think through how the new processes and underpinning working practices can actually benefit the people within the teams. Finally, let’s not forget the CIO and CEO. What cost savings have you made recently?!
-Such an approach buys time for the process implementation and will help to gain the much-needed stakeholder engagement across the organization. Experience suggests that failure to achieve these successes will typically double the resistance to the change and halve the support within six months. * I’d say within six weeks of your first implementation – let alone six months. ITIL processes have a strong track record of implementation success, along with some ‘sexy’ features for the end-users of ITIL based tools. So, it’s not that hard to get success stories flowing on a regular basis.
7. Maximum benefit can only be achieved if the impact each process has on another is understood.
-The ITIL framework is comprised of ten service management processes and one service management function. Every ITIL process supports, interfaces and integrates with at least one other process. *No, Between Service Support and Service Delivery – there are 10 core processes defined, the complete ITIL has many many more. Important to realise that ITIL is wider than Service Support and Service Delivery. The inter-relationships between processes is far more complex than a “integrates with at least one other” – e.g. Change Management impacts and is impacted by every other support process. A full reasoning is beyond the scope of this article.
-For effective development and deployment the relationship, impact and interdependencies across the ITIL framework must be clearly defined and understood. The close integration and understanding of the processes allows for the continual flow of up-to-date, critical and accurate information that in turn enables management to drill down and identify target areas for service improvement. *Whilst factually correct, the inter-dependencies are already defined for you in the OGC’s excellent series of Best Practice books. You need to understand them and appreciate them, but not let them rule your operation. Nothing is cast in stone. What works for you – works for you.
8. Prioritize process selection based on current maturity; don’t bite off more than you can chew!
-It is important to take a holistic view to ITIL implementation, however it is not imperative to implement all processes concurrently in order to realize operational improvements and a significant ROI. *In fact – don’t even bother trying to implement all processes concurrently. It will cost 5 times more and take twice as long in the medium term – and most likely FAIL! The best way is a structured approach where you implement the ‘core’ of each process either singularly or in matching pairs (e.g. Incident and Problem, or Configuration and Change). One the ‘core’ of ‘essence’ of each process is implemented, you can then re-visit each one and enhance to the next level. People take time to adapt to new tools, new ways of working, new meetings to attend and new ways of delivering service. It is far better to implement what your organization needs to resolve a business / IT Service challenge. You have to allow people time to adapt and step-up to the new operating level. If you change too much too quickly – even if it does match ITIL best practice – the people side will still let you down.
-Implementation of individual processes or the prescribed combination of processes can deliver the desired operational improvements. Processes should be selected based on the benefits sought by the organization and the ones that drive the most business value. * I mentioned the first part above, however with ITIL there are some underpinning processes that, at first, will realise little business value. For example configuration management and the CMDB. These are enabling processes that will “turbo-charge” the quality, speed and accuracy of your Incident, Problem, Availability… in fact… all of your new ITIL processes. But delivered at first – they offer little on their own. This is the paradox with ITIL.
9. Use success as a springboard for further improvement.
-Implementing ITIL is a strategic commitment and will take many months to fully implement. During this time many different parts of the IT organization will be required to change. *Agreed.
-In this sort of environment it is important to also implement a program of continuous improvement (e.g. a "plan, do, check, react" cycle). First this will ensure that improvement is actually delivered as expected and, second, it will help to build further improvement rather than assuming the job is done and risk slipping back in to old behaviors. *Once you embark on your ITIL journey – you have put yourself on the continuous improvement treadmill. But this treadmill has not got a big red ‘stop’ button. It trundles along at a pace dictated by the business, or your internal strategy. You really have no choice but to continue to improve, change, mould, tweak your processes (people, capabilities, tools etc). Stand still and the treadmill throws you off. Putting all this positively – you have the right path to ALWAYS advance and continuously improve your environment!
10. Technology
Combine process and tool activities from day one as part of a single solution approach.
-Implementing a service management tool will support the streamlined processes, automate tasks and manage and distribute information. Knowledge management, e.g., the re-use and integration of information, is a critical component of the service management tool. *Mmmm, difficult area this one. The tool should certainly support the working practices, process flows and standards and policies you have in place – NOT – the other way around. However, integrating the knowledge management aspect of tools is notoriously lengthy, costly and difficult for Service people to continue to evolve. Not impossible – just difficult. Again, done properly and your support costs can fall dramatically, as level 1 support staff can now perform many of the tasks that only (the more expensive) level 4 could do previously.
-Integrating data control processes with the tool will ensure that information is current and continues to add value to the service management processes. *You’re only as good as the accuracy and timeliness of the data that populates your tools. Rely on tools? You need to rely on the feeds and to those tools and the original sources of data.
-Implementing ITIL is not just about evaluating and revising processes, it is about change: changing the way people work and are rewarded; changing technology platforms; and changing behaviors across an entire organization. *You don’t necessarily need to change technology platforms to implement ITIL. You do need to change the way people work and behaviors.
So, that's it. Some points we totally agreed with, some of Isabel's comments and thoughts were very interesting, but also in our view some statements made ITIL look like a heck of a lot bigger and more complex that perhaps it 'has to be'.
Latest Resources (June 2006).
New! Visit the latest Blog from the creator of Dr. ITiL – covering ITIL Version 3 Refresh, Service Catalogs, CMDB, Foundation Exam Tips and ISO/IEC 20000 Knowledge. There’s a variety of free PDF and Powerpoint downloads available to help you plan, implement, deliver and improve your ITIL environment.
Visit the IT Service Blog
New! Learn the Step-By-Step Proven Strategies for Successfully Implementing ITIL. Free Audio and E-Book Downloads - Plus Special Bonus Resources.
Visit Ask The Service Expert
To be honest most of them are rubbish - but Isabel Wells (writing for CIO update) seems to have touched a few of our buttons.
So, we decided to give her top 10 implementation tips a good walk through and based on our collective experience, provide some feedback to each point, as follows.
[to read the original article in full, click here ]
Top 10 Tips for ITIL Implementation - Plus critique by Dr. ITiL
1. Approach ITIL implementation as part of the IT-wide strategy, and use it to guide all other strategic initiatives.
-ITIL process implementation has significant IT-wide impacts; it is not an isolated initiative. * TRUE.
-To avoid both resource and programming constraints, implementation must be aligned with other global and regional programs, IT initiatives and sourcing or supplier initiatives. * TRUE, as with any large Programme.
-A portfolio management approach should be taken to understand the alignment and priorities of all initiatives in addition to the overall benefits to the organization. * TRUE, though this is standard with any large Programme.
2. Consider the post-ITIL organization before completing the process design.
-Introducing ITIL-based processes generates requirements for new functions and roles, which could impact the current service management structure. *Absolutely. Different people are required to perform different duties, at different times. This is certainly one of the most challenging – but often NOT thought through areas of implementing ITIL. The new organizational structure is also a potential source of much discomfort for people, if communication and transformation planning is badly handled. People need to know where they are going, the benefits to be sold to them personally, and they need support and guidance with making an effective transition. *Warning: Sizing Service Teams is notoriously difficult. Can anyone point to “sizing models” that offer excellent guidance? I have never seen any. Usually sizing service teams is based around part considered workload analysis and ‘best estimates’. Hardly scientific!!
-Prior to completing process design, understand the roles and functions required to support the processes; giving specific consideration to the supplier/internal resource split. *Good thought. The internal changes in structure and roles, should also lead directly to a complete re-think on the roles and responsibilities of Suppliers. This could, in turn, lead to contractual re-negotiations. Depending on resource levels internally, there could be an opportunity to either out-task more responsibility to Suppliers, or to reduce contract costs and take more responsibility on in-house.
-Consideration must also be given to the governance structure needed to guide and support the new IT organization. Establishing a transformation program ensures that the structure from which to hang ITIL is secured and operational prior to process implementation. *Totally agree. Excellent governance (say, with a transformation board) to regularly monitor progress and assist programme managers by resolving their issues and mitigating risks can make ‘all the difference’.
3. Engage, engage, engage. Continuous communication is required at all levels of the organization.
-Implementing ITIL impacts the full spectrum of the organization’s employees. Because of this, it is critical to understand the impact at each level within the organization and the value each brings to the program. *Understanding – at all levels – is only the first stage though; the second point is where the action happens…see communications below…
-Subsequently, engagement, communications and training are absolutely key to success; from the initial engagement of senior stakeholders to the manager-level ITIL training of new global process owners. *Engagement and communications shouldn’t just stop at the manager level though. EVERYONE should receive appropriate briefings, especially analysts and coordinators who do the ‘real’ work everyday!
4. Set realistic expectations about benefits realization and establish a baseline from which to monitor improvements.
-Change within any organization takes time to be accepted and implementing ITIL is no different. Implementation of ITIL focuses on improving customer service and as the processes mature the subsequent ROI will be recognized. *Fine in theory, however how many of us actually went back and proved that the ROI was delivered within a suitable timeframe? It’s recommended that ROI be measured (a) before process implementation, (ii) a few weeks after, then (iii) as the process moves up the Capability Maturity Model. Note individual (or pairs) or ITIL proceses should be measured as opposed to the whole entire effort. ITIL is best implemented in a series of well executed, smaller projects.
-To determine the end result, focus the strategy and focus communications on improving service quality and establishing an early baseline of key performance indicators (KPIs) from which to monitor improvements. The chosen KPIs and their associated benefits should be business-focused and clearly understood so that effort is not wasted on measuring and interpreting superfluous data. *Good Advice.
5. Engage existing suppliers early.
-Existing suppliers and any subsequent SLA’s will be affected by the implementation of ITIL. The strategy for handling third-party engagement and establishing a robust communications plan must be clearly defined, with priorities focused on the desired supplier landscape. *Agreed.
-Early engagement with procurement and legal departments will help to support and address the ripple effect that occurs right through to existing contracts and SLAs upon implementing the new processes. An end-to-end SLA will also be ultimately required to support the operation of the new processes. *It’s not strictly true that SLA’s and contracts need to be changed just because you’re implementing ITIL – although if you’re implementing it successfully – then you will probably want to realise cost savings and change specific SLA targets / KPI’s. But it’s not mandatory to have to change contracts – it’s more about re-enforcing what you are aiming to achieve with your ITIL implementation.
6. Process
Identify and deliver the quick wins.
-It's "old" advice, but it remains fundamentally important to ensure that the organization achieves, communicates (and celebrates) early successes. *Absolutely! Deliverer a series of rapid, successive, well-executed quick wins right the way through your ITIL implementation programme. You need to keep everyone’s interest and keep generating positive news about the programme. For every process you implement there should be critical success factors defined in advance. Also, think through how the new processes and underpinning working practices can actually benefit the people within the teams. Finally, let’s not forget the CIO and CEO. What cost savings have you made recently?!
-Such an approach buys time for the process implementation and will help to gain the much-needed stakeholder engagement across the organization. Experience suggests that failure to achieve these successes will typically double the resistance to the change and halve the support within six months. * I’d say within six weeks of your first implementation – let alone six months. ITIL processes have a strong track record of implementation success, along with some ‘sexy’ features for the end-users of ITIL based tools. So, it’s not that hard to get success stories flowing on a regular basis.
7. Maximum benefit can only be achieved if the impact each process has on another is understood.
-The ITIL framework is comprised of ten service management processes and one service management function. Every ITIL process supports, interfaces and integrates with at least one other process. *No, Between Service Support and Service Delivery – there are 10 core processes defined, the complete ITIL has many many more. Important to realise that ITIL is wider than Service Support and Service Delivery. The inter-relationships between processes is far more complex than a “integrates with at least one other” – e.g. Change Management impacts and is impacted by every other support process. A full reasoning is beyond the scope of this article.
-For effective development and deployment the relationship, impact and interdependencies across the ITIL framework must be clearly defined and understood. The close integration and understanding of the processes allows for the continual flow of up-to-date, critical and accurate information that in turn enables management to drill down and identify target areas for service improvement. *Whilst factually correct, the inter-dependencies are already defined for you in the OGC’s excellent series of Best Practice books. You need to understand them and appreciate them, but not let them rule your operation. Nothing is cast in stone. What works for you – works for you.
8. Prioritize process selection based on current maturity; don’t bite off more than you can chew!
-It is important to take a holistic view to ITIL implementation, however it is not imperative to implement all processes concurrently in order to realize operational improvements and a significant ROI. *In fact – don’t even bother trying to implement all processes concurrently. It will cost 5 times more and take twice as long in the medium term – and most likely FAIL! The best way is a structured approach where you implement the ‘core’ of each process either singularly or in matching pairs (e.g. Incident and Problem, or Configuration and Change). One the ‘core’ of ‘essence’ of each process is implemented, you can then re-visit each one and enhance to the next level. People take time to adapt to new tools, new ways of working, new meetings to attend and new ways of delivering service. It is far better to implement what your organization needs to resolve a business / IT Service challenge. You have to allow people time to adapt and step-up to the new operating level. If you change too much too quickly – even if it does match ITIL best practice – the people side will still let you down.
-Implementation of individual processes or the prescribed combination of processes can deliver the desired operational improvements. Processes should be selected based on the benefits sought by the organization and the ones that drive the most business value. * I mentioned the first part above, however with ITIL there are some underpinning processes that, at first, will realise little business value. For example configuration management and the CMDB. These are enabling processes that will “turbo-charge” the quality, speed and accuracy of your Incident, Problem, Availability… in fact… all of your new ITIL processes. But delivered at first – they offer little on their own. This is the paradox with ITIL.
9. Use success as a springboard for further improvement.
-Implementing ITIL is a strategic commitment and will take many months to fully implement. During this time many different parts of the IT organization will be required to change. *Agreed.
-In this sort of environment it is important to also implement a program of continuous improvement (e.g. a "plan, do, check, react" cycle). First this will ensure that improvement is actually delivered as expected and, second, it will help to build further improvement rather than assuming the job is done and risk slipping back in to old behaviors. *Once you embark on your ITIL journey – you have put yourself on the continuous improvement treadmill. But this treadmill has not got a big red ‘stop’ button. It trundles along at a pace dictated by the business, or your internal strategy. You really have no choice but to continue to improve, change, mould, tweak your processes (people, capabilities, tools etc). Stand still and the treadmill throws you off. Putting all this positively – you have the right path to ALWAYS advance and continuously improve your environment!
10. Technology
Combine process and tool activities from day one as part of a single solution approach.
-Implementing a service management tool will support the streamlined processes, automate tasks and manage and distribute information. Knowledge management, e.g., the re-use and integration of information, is a critical component of the service management tool. *Mmmm, difficult area this one. The tool should certainly support the working practices, process flows and standards and policies you have in place – NOT – the other way around. However, integrating the knowledge management aspect of tools is notoriously lengthy, costly and difficult for Service people to continue to evolve. Not impossible – just difficult. Again, done properly and your support costs can fall dramatically, as level 1 support staff can now perform many of the tasks that only (the more expensive) level 4 could do previously.
-Integrating data control processes with the tool will ensure that information is current and continues to add value to the service management processes. *You’re only as good as the accuracy and timeliness of the data that populates your tools. Rely on tools? You need to rely on the feeds and to those tools and the original sources of data.
-Implementing ITIL is not just about evaluating and revising processes, it is about change: changing the way people work and are rewarded; changing technology platforms; and changing behaviors across an entire organization. *You don’t necessarily need to change technology platforms to implement ITIL. You do need to change the way people work and behaviors.
So, that's it. Some points we totally agreed with, some of Isabel's comments and thoughts were very interesting, but also in our view some statements made ITIL look like a heck of a lot bigger and more complex that perhaps it 'has to be'.
Latest Resources (June 2006).
New! Visit the latest Blog from the creator of Dr. ITiL – covering ITIL Version 3 Refresh, Service Catalogs, CMDB, Foundation Exam Tips and ISO/IEC 20000 Knowledge. There’s a variety of free PDF and Powerpoint downloads available to help you plan, implement, deliver and improve your ITIL environment.
Visit the IT Service Blog
New! Learn the Step-By-Step Proven Strategies for Successfully Implementing ITIL. Free Audio and E-Book Downloads - Plus Special Bonus Resources.
Visit Ask The Service Expert
The seven Sources Of Problems #5 - "User Error"
The people who use your IT Systems to deliver Service to your true end-customers are also a key source of Problems, writes Robin Yearsley.
Your business folks are often under tremendous pressure to deliver ongoing results within their business lines. They have no time, little patience and absolutely no sympathy for technology or IT Systems. Therefore when things go wrong (as they sometimes do!) they like to circumvent the usual support processes – like calling the Service Desk to report a fault, waiting for technical assistance and providing valuable information to assist your support services people.
I have painted a rather gloomy picture here already and perhaps that’s a little unfair. Within call center environments, where people spend tens of hours calling customers, users are only too happy when their systems fail – they get to do other work or take an early break! Remember – there business line is effective suffering from downtime and I’m pretty sure their boss won’t be happy with the situation.
So, against this background what are the typical reasons why Problems can occur with “User Error”?
User Education – or rather the lack of it! Often within the project delivery lifecycle, testing and education are some of the first activities to be cut back. This means that due to over-runs in the design, build and (sometimes) testing stages – there’s little time to actually education end-users on their forthcoming new IT system. As well as reducing the businesses ability to actually realise the benefits of the system – it leads to users making mistakes, “tinkering” and finding their own amazing “shortcuts” to get the end results that they require. There is really no substitute for quality education. It helps to prevent end-users circumventing how they are supposed to use their systems. Things you can do here are: maintain linkages with the IT education team, determine just how much education end users have received and make education a mandatory requirement on the business side of your system SLA’s; also ensure a local ‘escalation’ procedure (where education gaps are apparent) to let end users raise questions and receive answers for new queries is known and in place.
Purposeful Documentation – users guides, cheat sheets, ‘what to do if this happens’, ‘where to get help’, ‘what to expect from IT Support’ – are all examples of local documentation that can be carefully placed on or near the end-users desks to prevent “tinkering” and ingenious workarounds being applied. For example one Guy we knew in a customer service function actually created his own set of highly complex report writing tools within Excel, because he didn’t know that the report writing suite was only limited to his manager. He told his manager (to her amazement she didn’t appreciate HOW he was producing these reports) who immediately granted him access to the Report Suite. (Ironically, the Excel version did everything the team needed – so it stayed!!)
The delivered systems “fails to meet specified requirements” – This is more common than you perhaps realize. The system, as delivered manages to get through testing, user approval and is accepted into production – however for some reason the system doesn’t do something that it’s supposed to do. Some the end-user community find an ingenious way around this. In my experience this is usually something relatively complex about importing data and processing it against key dates, or exporting files between systems because the overnight automated routine keeps failing and the system cannot automatically recover. Users finding their own workarounds is fine in the very short term, often only lasting for that particular working day, however this is very temporary. Workarounds like this are often “triggers” for Incidents that are lying there, waiting to happen. To try to overcome this common situation, you must try to determine where the system fails to meet requirements and understand how this will be remedied.
Validation, robustness and ‘self-healing’ – It makes sense that the ‘stronger’ a system is (in terms of handling weird occurrences) then the less likely that you will see Problems with it further downstream. With the advent of object orientated coding methods, the ability of modules to self-correct and maximise the availability of the system is excellent. Take action during the design stages of new systems to ensure that the levels of robustness are where you would expect it to be – when balanced against the required level of systems availability by the business.
Some more ‘top tips’ to bear in mind with Source #5:-
1. Ensure there is really a problem to eliminate – be careful not to expend large amounts of resources on ‘red herrings’!
2. Ensure education is not ‘axed’ – Stand up for quality education. Not only does it help to maximise the benefits of a system – but it prevents Problems too.
3. Ensure systems are ‘fit for purpose’ – Check out the test results, work with user QA groups, get a good ‘feel’ for the forthcoming system before it enters production. Influence the quality of the final solution BEFORE it enters production.
4. Testing should include destructive tests that satisfy curious minds – It’s guaranteed that once a system goes live it will be absolutely hammered with every possible combination of data/keyboard presses and all sorts of eventualities that were never thought of during testing. To this end, some up-front destructive testing should help to find some of the more serious conditions that might occur after go-live. You do destructive testing, right?
5. Implement a ‘super-user’ programme – best of all – maintain an excellent relationship with the business user community. Form partnerships with key folks who act as ‘super users’ for different systems. They will help you to differentiate between real problems and ‘red herrings’ as well as help you get access to the right people and information should a real problem arise.
Tomorrow, we examine the penultimate source of problems #5 – How Production is Executed. In this source we explore how you run your environment and look more closely at internal controls and the effectiveness of your Problem Management process.
World's Largest ITIL Conference

World's Largest ITIL Conference Celebrating 10th Anniversay At The Bellagio, Las Vegas. Monday, February 12 to 15, 2006.
Pink Elephant Preparing To Bring The ‘Best Of ITIL’ To Milestone Event
TORONTO, ON – Pink Elephant, a global leader in IT service management consulting, education and events, today announced 10th anniversary plans for the International IT Service Management Conference and Exhibition – the premier event dedicated to ITIL (IT Infrastructure Library).
The 10th annual conference, set for February 12 to 15, 2006 in Las Vegas, will feature a full line-up of experienced practitioners, industry gurus and special keynotes.
Exciting new tracks will include:-
Leading Change – Based on the eight steps for leading change by Harvard’s John Kotter
ITIL Service Support and Delivery – Two distinct tracks zeroing in on core ITIL processes
Pink University – In-demand ITIL seminars taught by Pink’s own expert consultants
Another popular track returning to the program is IT Business School, taught by respected North American business school professors.
Other highlights will include an entertaining sketch, ‘What’s So Funny About IT?’, from the LaughingStock Comedy Company; the ITIL Awards, recognizing the best ITIL projects in the practitioner community; and the Exhibition Showcase, featuring a wide selection of ITIL compatible products and services.
ITIL is the most widely accepted approach to IT service management and was originally developed by the UK Office of Government Commerce (OGC). It is a non-proprietary set of books that outline a consistent and coherent set of best practices for the provision of IT services. Pink Elephant is recognized as one of the foremost champions of ITIL, and was the first to bring ITIL to North America in 1997.
“Year over year, we have noticed an increasing interest from global organizations that not only want to learn ITIL theory, but also want to understand how they can adapt the framework to tackle top IT issues such as governance and security,” says Pink Elephant President and CEO, David Ratcliffe. “Over the next ten years, Pink Elephant will continue to lead the way and create dynamic programming at the Conference that equips IT professionals with the most essential and up-to-date information.”
While the main focus of the ten-track, 100-session program for the 2006 conference is ITIL best practices, inspiring keynotes will also explore how to adopt best practices in other areas of life. Expert political consultant Allan Pease will share his tips for effective interpersonal communication; and Jim Murphy, formerly of the US Air Force, will explain how business professionals can apply the ‘Flawless Execution Model’ used by fighter pilots to improve team performance.
The 10th Annual International IT Service Management Conference and Exhibition is taking place at the luxurious Bellagio Hotel in Las Vegas, rated among the world’s top ten hotels.
Pink Elephant is offering its best ever Early Bird Special price of US$1,000 to guests who register and pay for the conference by October 31, 2005. The regular price is US$ 1,695. For complete program details and to register, visit http://www.pinkelephant.com/ or call 1-888-273-PINK. About Pink ElephantPink Elephant is privately owned and is headquartered in Toronto, Ontario, Canada with operations worldwide.
Pink Elephant works with organizations, including many companies listed in the Fortune 500, to improve the quality of IT services through the application of established best practices, such as the Information Technology Infrastructure Library (ITIL). For more information, please visit www.pinkelephant.com.
For more information or to arrange an interview, please contact:
Ann LamanesAssistant Manager, Marketing Services – Communications
Pink ElephantPhone: (905) 331-5060 Ext. 295
Toll Free: 1-888-273-7465
E-mail: a.lamanes@pinkelephant.com
Subscribe to:
Posts (Atom)


